 Skip to content
Skip to content 

The Cloudflare Outage
On June 21, 2022, Cloudflare suffered an outage that affected traffic in nineteen data centers. The outage was caused by a change, part of a long-running project to increase resilience in their busiest locations. The result was a 75-minute outage. While 75 minutes may sound minor, consider that Cloudflare handles an estimated 10% of all global HTTP/HTTPS Internet traffic (19.2% of all websites, including Discord, Zerodha, Shopify, Canva and many more). In this context, the impact was much more significant.

What went wrong?
Remarkably, Cloudflare was transparent and shared a detailed root cause analysis (RCA) on the outage, which is not a common practice followed by many large service providers.
The outage resulted from routing policy changes to the existing services infrastructure, mainly L3VPN/ EVPN services connecting the network endpoints to external ISPs that execute critical internal services such as DNS, BGP routes, and more. These routing policies control the routers’ decisions regarding routes to be exposed to both external and internal parties, as well as ones to be redacted. It also includes the attributes to be modified to control traffic flow in and out of the company’s automation system.

To summarize, the problems that occurred with Cloudflare can be attributed mainly to creating and ordering routing policies, exacerbated by adding new policies or statements to the current network automation system. Since, by default, new policy statements are appended at the end, they need re-ordering so that routers can make correct decisions to accept or reject a route.
For some, Access-List (ACL) can help understand the crux of the problem efficiently. An ACL statement determines which packets are permitted to enter or exit an interface. Similarly, a routing policy decides which routes are imported or exported from a BGP route table. Sequencing both is critical to ensure the proper feature function.
In retrospect, Cloudflare’s current automation systems may have had difficulty perceiving the intent of the changes, or the instructions may not have been adequate to result in the intended behavior. So, given these challenges, there are a handful of ways to prevent similar outages in the future, including:
- Clear/Precise requirements: The automation and operational teams should work together to better understand a device’s behavior before automating it. Automation teams should also receive clear instructions/feedback at every step. If an automation system is limited in its capabilities to add newer configuration blocks to an existing configuration, the requirements should explicitly establish the hierarchy of the new configuration.

Fig: Sample BGP policies
- Automated Pre/Post-Checks: As a part of the method of procedure (MOP), extra checks can be run on the config diff generated by routers in most cases by issuing commands such as “show | compare.” MOPs should be revisited after every major network event, OS update, etc. Senior team members should identify configuration changes and the potential impact. In general, best practices should continuously be incorporated into any MOP.
- Continuous Validation: Testing before deployment in the network industry is a relatively overlooked practice compared to the software industry. Building testing infrastructure parallel to automation infrastructure can be a game-changer in such scenarios.
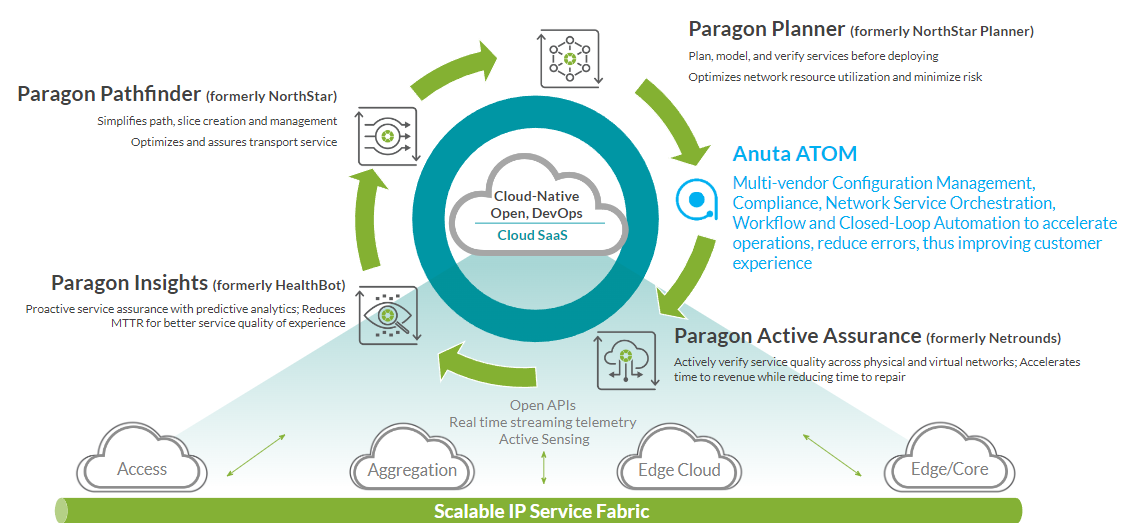
Fig: Anuta ATOM placement in the Juniper Paragon Automation Suite
Given the advent of the latest tools such as Batfish, Flare Networks, Juniper Paragon Planner (part of the Paragon Automation Suite), and Docker containers, more testing can quickly become an integral part of any CI/CD pipeline. This step can help immensely in providing a clearer picture to network engineers regarding the impact of a given change in a network, serving as a significant second cross-verification step.

Fig: A logical diagram of a CI/CD Pipeline
- Management (DCN) Network: The data communication network (DCN) refers to the network on which network elements (NEs) exchange Operation, Administration, and Maintenance (OAM) information with the network management system (NMS). It is designed to have uninterrupted communication between network devices and NMS. Enterprises should also consider investing in setups that can access critical devices via CLI/API login during significant outages. The uplinks of a given network should also be placed with a different Service Provider with complete path diversification for resiliency.

Fig: An example High-Level Topology diagram of a DCN Network.
With all of the recommendations above, how does Anuta Networks ATOM (a component of the Juniper Paragon Automation suite) help prevent network outages?
These six capabilities serve as ATOM’s superpowers:
- Intrinsic Benefits of Automating With ATOM: The ATOM architecture can address many problems which haunt traditional CLI-based automation systems. ATOM’s feature-packed service models based on YANG can be highly effective for config provisioning compared to CLI push. When new policy statements or policies are added to the service model and called into routing instances, the “ordered-by user” option in the leaf list is used to prioritize/order these statements. This facility in the YANG model results in the removal and re-addition of statements at the device level in the desired order.
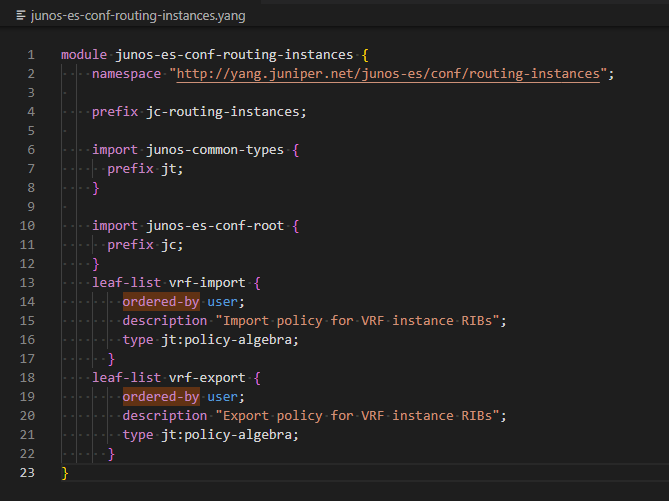
Fig: ‘ordered-by user’ statement used in the juniper routing-instance yang model

Fig: ‘ordered-by user’ statement used in the IETF-ACL yang model
2. ATOM Dry-Run: ATOM’s “Dry-Run” feature shows the complete list of changes to be performed on network devices by comparing them to the latest config backup. This feature is a checkpoint where network engineers can verify changes going into the network days before going live. The output is in JSON, and workflow scripts can be used to parse the JSON output.
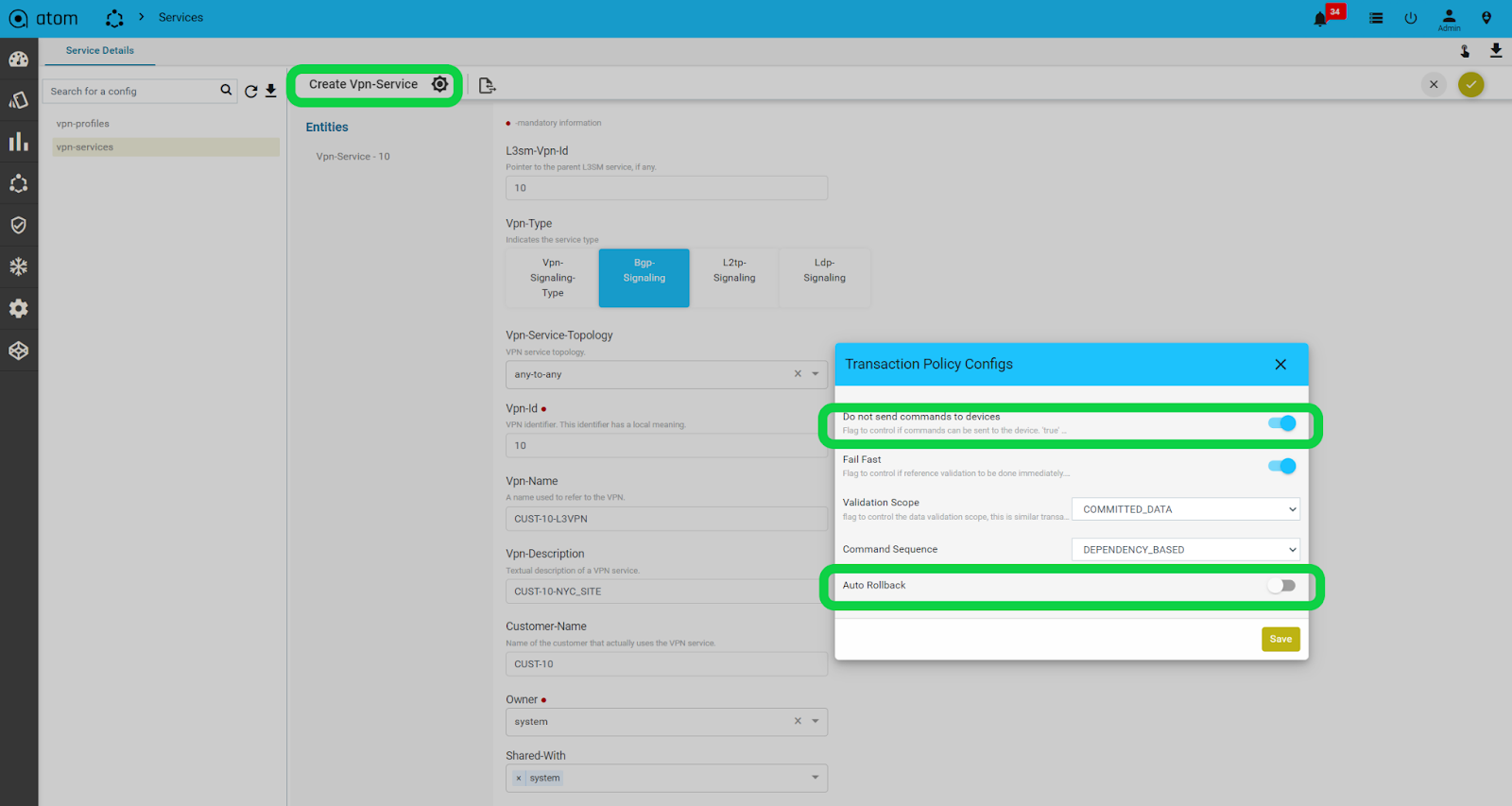
Fig: A Snapshot of ATOM services deployment and checking how new service config looks against config backup and not on-device config
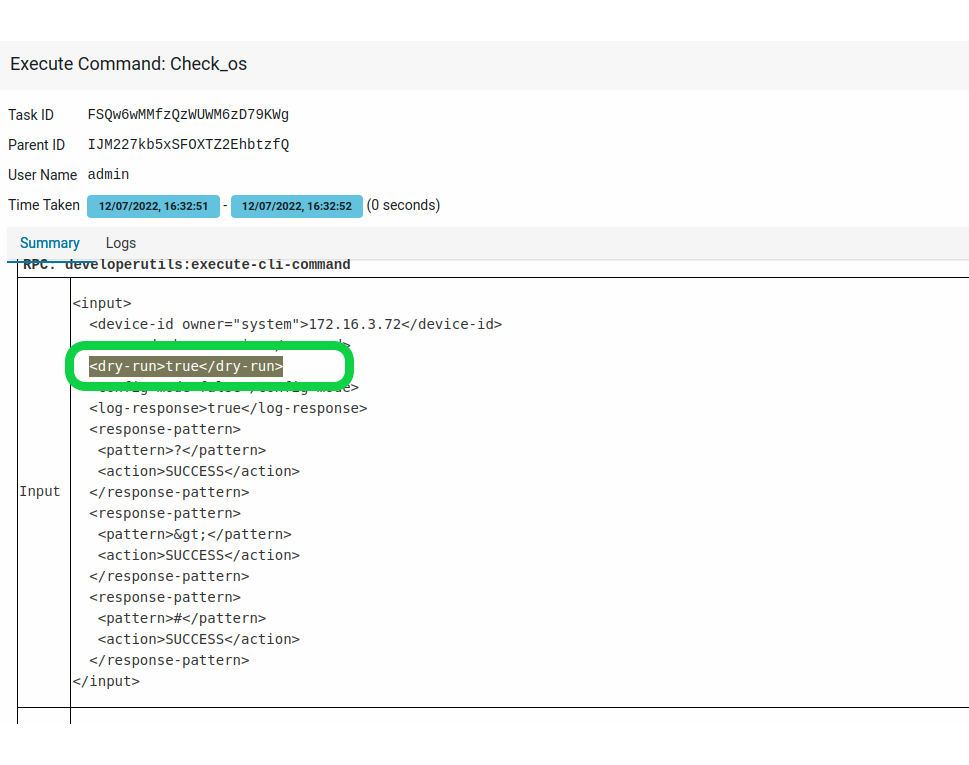
Fig: A snapshot of a task showing a successful dry-run check
3. Reducing Recovery Time During Outages: Different teams formulated multiple resolution measures to address the outage in the Cloudflare example. Eventually, teams and engineers overrode each other, leading to confusion and an extended mean time to recovery.
ATOM has a feature that pulls device configurations at regular intervals or during any events resulting in configuration changes. This configuration tagging feature can be handy if the change involves many devices. With just a few clicks, one can immediately revert devices to the golden/previous best state.
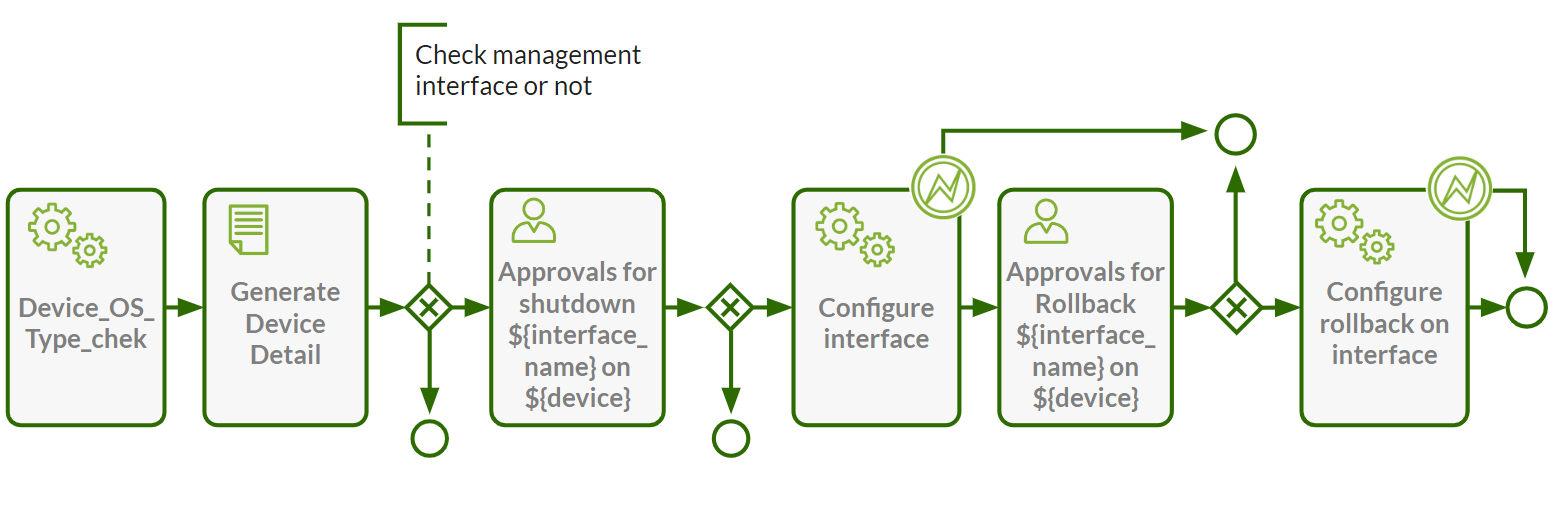
Fig: A snapshot of ATOM Workflows showing config tasks with different task level directives
4. Integrating ATOM Into An Existing CI/CD Infrastructure: ATOM can also act as the initiator of CI/CD pipelines and not just be a part of them. A pipeline initiated with an innovative tool like ATOM can be more precise and informed of what changes are pushed into a given test and production environment. Furthermore, one can introduce code reviews and approvals to minimize accidental changes.
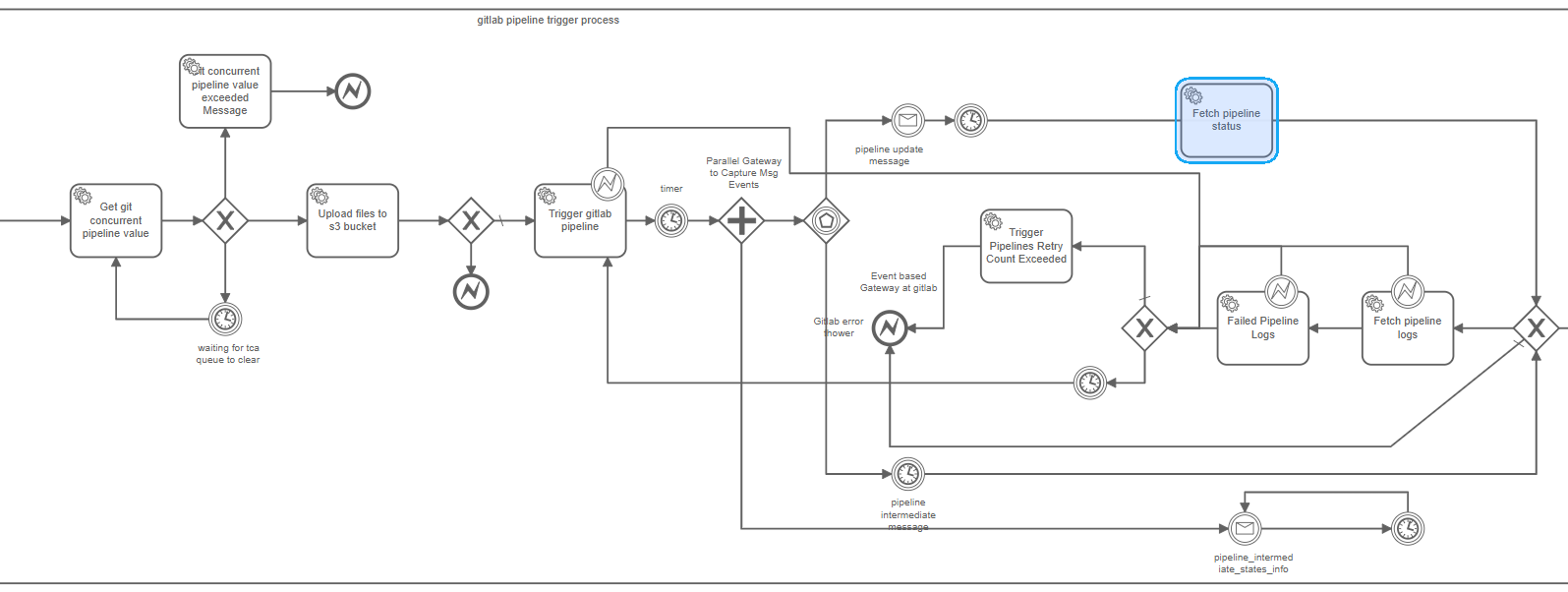
Fig: A snapshot of an ATOM workflow that interacts with GitLab CI/CD pipeline
5. The New-Era Closed Loop Automation: With its SNMP/Syslog/Telemetry collection, ATOM eases the task of monitoring. Any sudden changes in network behavior, such as heavily increased or decreased route counts, a dip in traffic, or more, can be used as a trigger to start a workflow (commonly called Closed-Loop Automation).
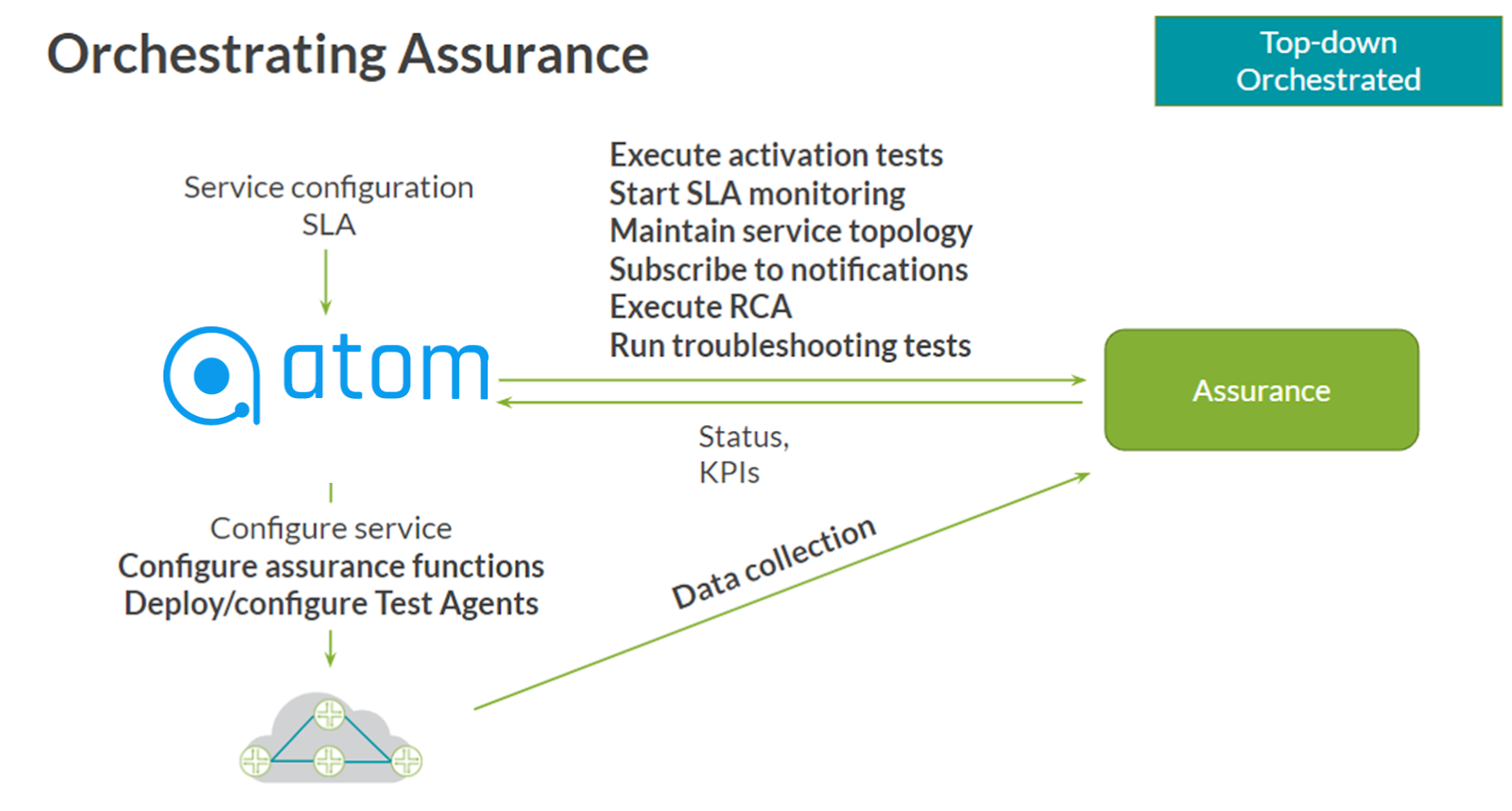
Fig: Integration of Orchestrator with Assurance Module for Closed-Loop Automation
Continuous data collection from devices using SNMP/Syslog/Telemetry can initiate multiple remediations. Examples include starting config archival tasks, troubleshooting workflows, detecting a dip in KPIs using service monitoring, and generating notifications internally or externally via slack/email.
6. Automated Compliance Validation: Another critical observation, in the case of the Cloudflare outage, was the delay in resolution. In hindsight, this is understandable given the scale and scope. However, ATOM could have offered a quicker resolution.
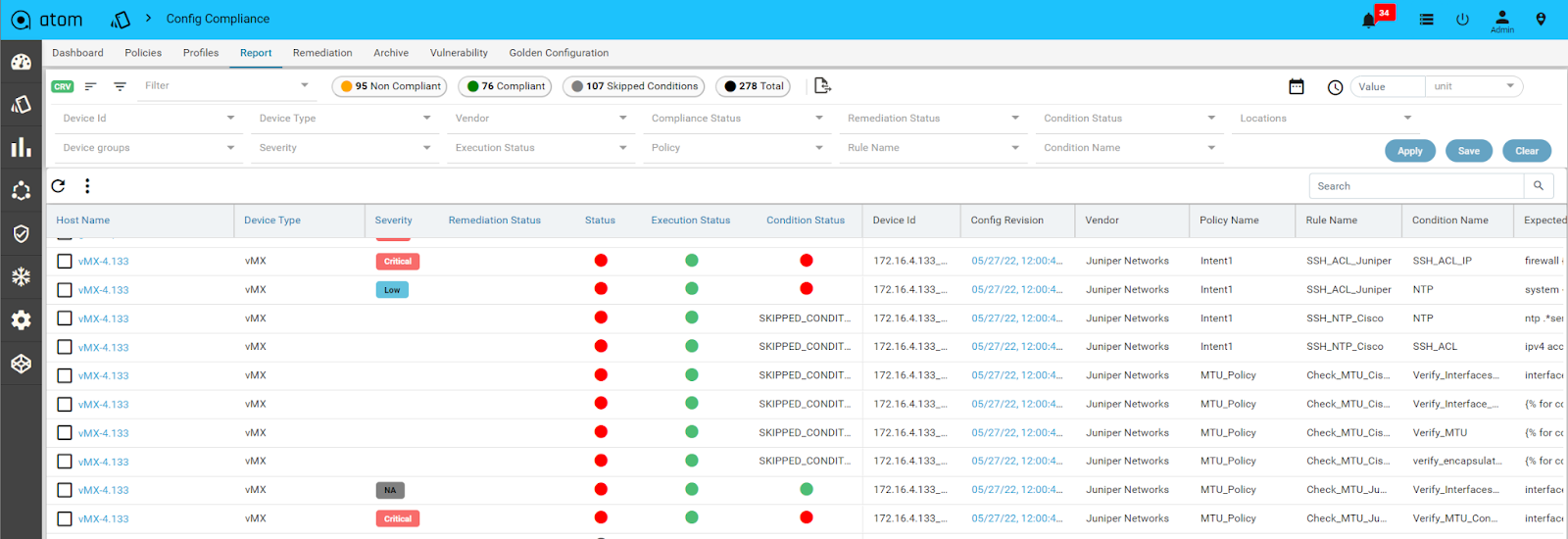
Fig: A Snapshot of ATOM interface showing Config Compliance Check Reports
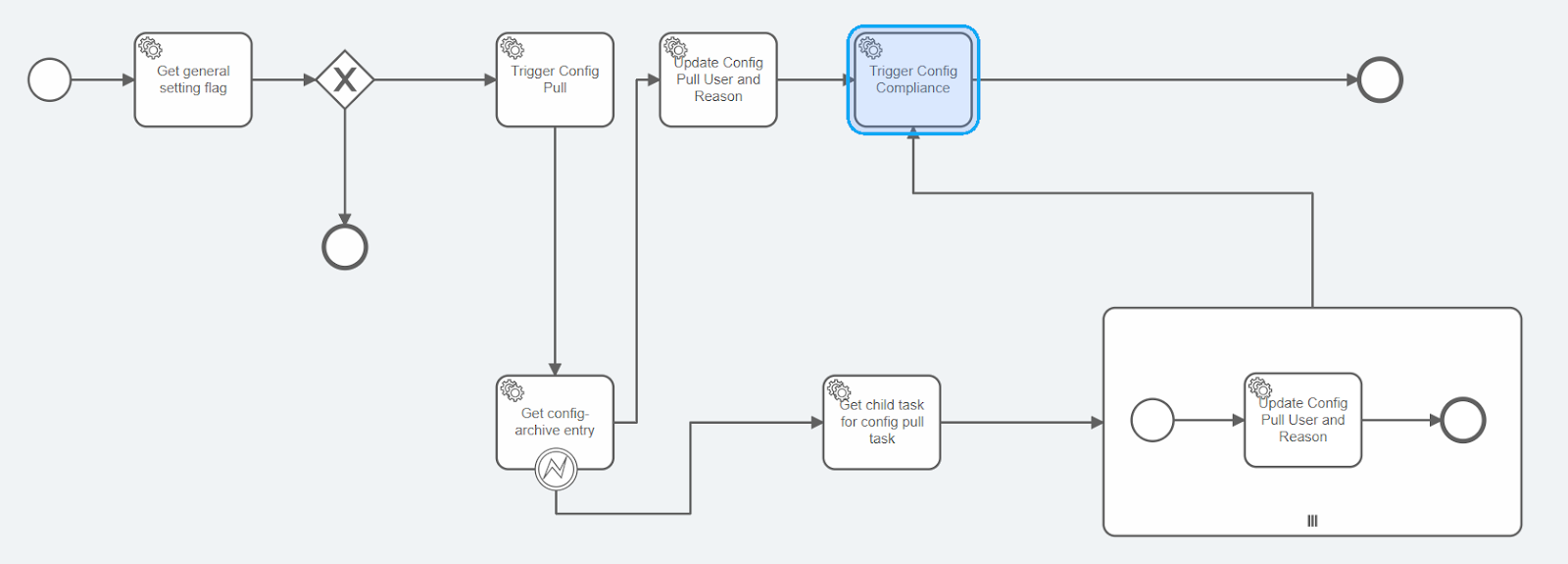
Fig: An ATOM Workflow snapshot showing automated remediation of identified compliance issues
A network device such as a router transforms from one state to another, defining its performance. If one takes a snapshot, that state is frozen in time. The traditional approach of taking config snapshots creates stale data immediately, resulting in the loss of configurations applied after taking the snapshot. Conversely, ATOM validates the restored configuration against the stated intent through automated verification checks, generating a compliance audit report. Any violations can be automatically remediated, thus reinstating the intent.
Conclusion:
Automation is an excellent tool for improving productivity and consistency, but fine-tuning your network requirements can be daunting. To address this need, Anuta Networks ATOM offers the necessary checks and balances with its solution capabilities backed by a proven microservices-based architectural framework that delivers scale and resiliency.
The Anuta Networks team is tapping into a significant experience that spans working with service providers and large enterprises. As a result, we can serve as a trusted advisor to help with your internal automation efforts and journey.
Want to learn more? Visit the ATOM product page and contact us for a live demo.
Additional Contributors: Atmesh Agarwal, Rohit Patil, Sukirti Bhawna.


