 Skip to content
Skip to content 

In a multi-vendor world, you can’t rely on automation scripts to support the ever changing network infrastructure. Network Service Orchestration is quickly gaining adoption. Anuta Networks is announcing NCX 5.0 release using YANG model driven architecture to deliver vendor-neutral, extensible and scalable platform that accelerates:
ANY network service (be it segmentation, branch automation, DCI) across ANY network domain (Data Center, Campus, Branch, Wireless) for ANY vendor platform (Cisco, Juniper, F5, Citrix, Palo Alto, HP, Brocade) using ANY southbound interface (CLI, NETCONF, XML, YANG, API).

Praveen Vengalam (Anuta’s Co-Founder and VP of Engineering) discusses the motivation behind YANG (which is a IETF standard, btw) and how the NCX platform scales to thousands of devices across hundreds of locations with a distributed, micro-services based, multi-tenant architecture validated in Fortune-500 enterprises and large MSPs world-wide.
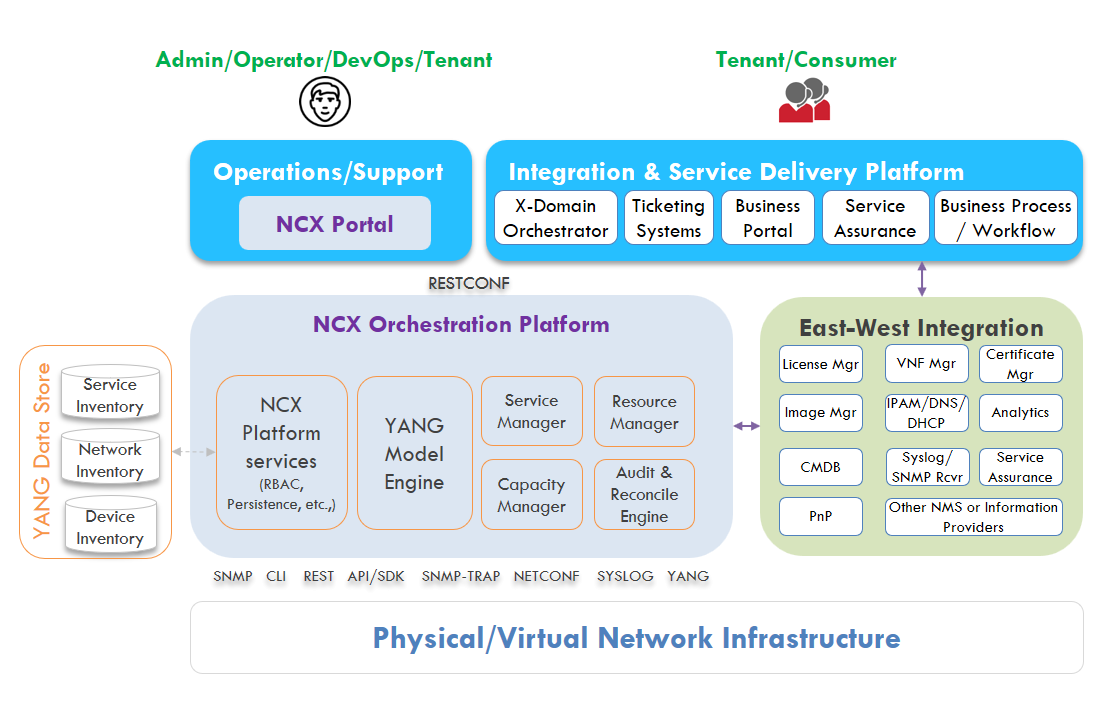
Anuta’s Kiran Sirupa (Sr. PLM) says that Anuta has developed YANG based device and service models for 100+ different platforms from 35+ industry leading vendors. The YANG models enable them to easily add new device and service models within days to support new technologies, vendors and use-cases.
Podcast Transcript
Packet Pushers Podcast Introduction
0:01 Today on Packet Pushers, another chapter in the book of automation. Anuta Networks, our sponsor today, writes this chapter with an update on their NCX product, a vote for YANG modeling, real-world network intent, a GUI they are proud of, and a discussion of how actual customers are using the product.
I am Ethan Banks along with Greg Ferro. And let’s ask our guests to introduce themselves today, starting with Anuta’s Kiran Sirupa. Kiran, could you please introduce yourself to the Packet Pushers audience.
Anuta Team Introduction
0:26 Kiran: Hi Ethan, this is Kiran Sirupa. I’m a senior product manager with Anuta Networks.
0:33 Ethan: Very nice to have you on the show today. And also joining us is Praveen Vengalam. Praveen, say hi to the good folks out here listening.
0:41 Praveen: Hi everyone, this is Praveen Vengalam, this is one of the VP of the co-founders of Anuta and the VP of engineering.
0:48 Ethan: Wonderful, thank you Praveen for joining us. And Kiran let’s start kick off a question here with you.
It has been a while since we spoke with Anuta. If you are a long time Packet Pushers listeners, you know Anuta has been on the show before. The last time we spoke to you guys was all the way back to Weekly Show 143 – April 2013. So things have changed a bit, right. Tell us what the NCX product looks like today Kiran.
NCX Introduction
1:09 Kiran: So Ethan, Ethan, Just a quick recap for the audience, Anuta’s NCX delivers Network Service orchestration for various networking domains. It helps administrators and operators deliver network services within minutes. NCX uses YANG modeling framework and delivers an extensible and scalable platform…for brownfield and greenfield deployments. Using NCX, you will be able to orchestrate ANY network domain (such as Data Center, Branch, Campus, Wireless, Cloud) and ANY network service (such as Application Delivery, Branch Connectivity, Segmentation, Firewall Automation, Cloud Interconnects) for ANY vendor (such as Cisco, F5, HP, Checkpoint, Palo Alto) and ANY southbound interface (including CLI, NETCONF or API). Multiple Fortune-500 enterprises and large MSPs have deployed NCX.
2:06 Greg: That’s really quite a big claim, right. So when I think about that, you are sort of saying that, Anuta NCX products isn’t just about SDNing a few vendor’s with your product. You are claiming for any networking type, Campus, WAN, Data Center, Wireless, for any type of domain, regardless of the product or platform that’s underneath. That’s a big claim, right. And we are going to have to talk about in the show. So you are going to have to step up.
Application Delivery Example
2:31 Kiran: Yes, I’m very proud to say that, and I’ll give you one example. A very large financial institute in US has deployed NCX. And they have the alphabet of vendors as I mentioned. They have Cisco Routers, F5 Load-balancers, Checkpoint Firewalls, Verisign Certificates, Infoblox IPAM and VMware Virtualization.
The NCX platform enables Cloud architect to express the application delivery requirements – whether it’s the segmentation policies – (such as configuring VLANs, VRFs, Firewall Contexts, Route Domains. As well as the application profiles that require us to configuring multiple endpoints such as load-balancers, firewalls, IPAM, DNS, Certificate Manager and Web Proxy. And Anuta’s NCX has been able to automate and introduce self-service for this multi-vendor infrastructure.
3:33 The key strength of the platform is the ease with which you can express the business requirement or business intent and the comprehensive vendor support.
3:40 Ethan: Okay, this is drilling into where you guys at ANuta have heads down on software engineering for quite a while now. When you came to market it was, more of a point solution with; now you’ve really enhanced the platform to cover all sorts of things. And you said a lot of key things in those last few paragraphs here. And you mentioned segmentation policies, VLANs, VRFs, Firewall Contexts, Route Domains etc. And being able to deliver that across all different kinds of platforms. Which Typically we think of a segmentation in an environment often containerized. While the routers are doing this, and I want to stitch this into the firewall. I got to do it this particular way because every platform is kind of different. The verbiage is different. You are suggesting that, you will just via business intent, I’m going to express to NCX what it is I need the network to look like. You’ll deliver that segmentation across all of the different network services that I’ve gotten under my care and feeding.
4:35 Kiran: Exactly, we will go in much detail further. But all we need from the customers is the business intent and what they want to achieve for that given application, or the given use case .NCX has all the smarts to build the end-to-end service for the infrastructure.
4:55 Ethan: What version is the product at now? The last we saw was quite a bit earlier. I remember seeing some of the GUI and so on. What version are we at now, and what specific things have changed in the new version?
NCX 5.0 Platform Introduction
5:03 Praveen: NCX is at release 5.0 as this point in time. And we have brought in a significant number of capabilities into the platform to kind of address what Kiran has just alluded to. So how do we express business intent is where the smarts are within the product. And we use the standards based platform. The IETF Yang Model language to express the business intent. We also lean on any of the native interfaces that come from the infrastructure providrs, like the equipment vendors. And the interfacers could be CLI, the interfaces could be YANG natively, the interfacers could be any other APIs for that matter. But what NCX provides is a layered way to obstract the underlying APIs so that we can map the underlying device vendor APIs into the business intent. So ultimately when we look at this top down, we have a business intent, we have a mapping layer that maps the device intent. So this is how we make it easy to have this separation between the business intent and the device intent. So this is actually what facilitates our customers and partners to describe any intent that they have in an easy way and in a way that is. standardized and in a way that is portable across any platforms that could potentially work off of Yang models. This is actually what we bring to the tables as a part of the Yang Based Model Platform.
6:27 And the fact that some of these vendors already have models, and there are already industry best practices for some of the use cases. For example the use case that Kiran talked about. Working with large enterprise customers we, have come to realize that for, example, let’s say, they want to deploy an application in an enterprise data center. There is a significant commonality, you deploy a bunch of real servers , you open up a firewall rules. You secure a IP address in IPAM. You go do a bunch of stuff along those lines. But how do you describe all of those activities. That’s actually where we come in. We kind of have innovated significantly in this area to ease the process and ease the mapping logics so that you can stand up a service in a matter of minutes, once it is deployed. We can take it from concept to deployment within a matter of days to weeks.
Why YANG?
7:12 Ethan: You’ve parked on Yang. And you say Yang Model is how we are going to do this. It’s the way that we are going to describe service intent. And you are using IETF and some of the emerging IETF models, and the Yang models that have been published there. But I’ve heard some criticisms of Yang. You know, it’s not good enough, it doesn’t really do sufficient job. Why did you guys decide to use Yang even when maybe some other people are kind of moving in a different direction?
7:34 Praveen: Yeah, one of the criteria is for us for us to choose a standard based platform so that we kind of adhere to something that is already out there. Some amount of research, some amount of vetting already happened, as to what it could be used for. So if you’ve seen in the industry that there is not a whole lot of other alternatives. Again that is not a good sign as well. But at the same time, that is about the only thing that has got the significant backing from multiple different. Equipment vendors, and multiple different service providers. And multiple-other orchestration platforms also that have a good traction in the market.
8:10 Greg: Yang is very popular. I was just at the IETF last week and, as networking engineers, you may not have heard a lot about Yang, maybe yet. The way I like to think about it is, remember we stood by the SNMP MIBS as the universal way to connect the devices to get data? Conceptually, it’s not at all like that but in simple terms that’s how you say, I want this data from this device. And the Yang model is the way of defining that. It is standardized like, in the same way that, we do have a standard description and the IETF is working very hard to get this sorted out.
8:41 Kiran: I also think there are some misconception because wherever you see. YANG and you hear Netconf. So people assume that you need to have Netconf to support YANG.. And not all the platforms have Netconf. What ANUTA has done is, we have developed the device adopters for platforms that don’t have Netconf. That’s why we are able to support so many vendors, even if they don’t have Netconf support. You will see that with Anuta’s platform. You are not limited to a few vendors.
Multi-Vendor Support
9:09 Ethan: Okay, so we’re using Yang, and I agree, it certainly is popular, and it makes sense why you guys have latched on to it. So that adds up for me. Put me in the customers’ shoes here. If I am a customer, and I’m getting ready to stand up a complex service. And you told me NCX can do a lot of this hard work for me. What do I have to do to get a service stood up.
9:34 Praveen: As we briefly went over the main building blocks in prior note. So the first building block is the device modelling. And this is where we look at the device APIs and what capabilities that they bring to the table. And see if the API is readily consumable.. For example the API could be a native Yang Model, or it could be CLI or it could be API. Depending on what the underlying model is. We take the underlying native model and map it to a common model. And the common model could be a model that IETF has published as apart of their drafts. There is no drafts available there,. Anuta NCX is going to provide that out of the box; that model. And we also provide a SDK for customers to go and develop the Yang Model and map it to the underlying device layer.
Platform Extensibility
10:16 Ethan: So let’s talk about that for just a second. So if there is no model, you are saying that you have an SDK that a customer can then write to and say, okay, this is the model, these are the services represented in this model by this device. And then plug that in via the SDK, so that they can have the same service and support for this device that was previously undescribed.
10:34 Praveen: That is correct, and once you have that model available, and also to reiterate the fact that, more often than not, the customers that we work with, they never really have to go through the device model development. The reason is, since we are working with so many customers, more often than not, you are going to get the least common denominator across the whole set of use cases that we have been working on, where the model comes through out of the gate.
11:00 Praveen: In rare cases, if it is a really cutting edge platform, and the customers cannot wait for this to be made as a part of the release. The release itself takes a couple of weeks for us, and we just have very frequent releases for the device patches and the device models. If it can’t wait, the SDK is available that we have developed to make sure that we have a open platform that is fully developed for customers.
11:20 Praveen: And once we have the device models, we now can operate using the RESCONF API against the device models, that is the lowest level of integration that we would have against device. And then now comes the Business intent, this is where you are describing your service model. And you are saying, I want to describe the service same example VIP and a whole bunch of servers, services and firewall rules. By all means you describe that and you use the mapping logic to map that and map it to the Device models that have just being published or have been developed by the customers himself. And then comes the NCX release. and the building management tools. So once we feed the service models, once we feed the device models in, we are going to auto generate the code wherever required… Because we are going to have this mapping from the service model to the device model. And then once that code gets generated, it gets packaged and we can install the package onto a NCX system, and the system is liven now.
12:11 Praveen: This is very much a devops kind of flow where you design, develop build deploy test. And you do this again to just make sure you get the quality that you desire. And then you are off to production.
12:22 Ethan: It sounds like lego blocks, there is just different pieces along the way, and you plug these in, and then you end up with a system at the end. And again, the lego architecture here, the way it is resonating in my brain. If I don’t have a specific device model or I don’t have a specific service. I just build that block and then I can plug that into the system, and I end up with, wow, to go with the devops analogy with running code at the end.
12:43 Praveen: That is correct Ethan. Having worked with all of these customers, the way it works with the device model is that it is more of a community based approach. We collaborate closely with our customers and partners to build our roadmap in such a way that the device model caters to the industry requirements. And the roadmap of our customers also. That’s actually why we are confident that more often than not, at the device level, we have what the customers and partners need. Because when the partners develop something they are going to send it back as a community. And this is what we take to the market continuously.
13:18 Over the course of the last few years we have built support for more than 35 vendors and 100 plus platforms. This just gives a significant amount of coverage to a lot of market segments, campus, branch, data center, a whole bunch of use-cases within those domains.
13:35 Ethan: 35 vendors with a 100 plus platforms, and you’ve mentioned that, it doesn’t seem to take that long if someone brings a new device to ANUTA that they like included in the system. Just a few weeks, is that fair to say?
13:42 Praveen: Yeah it’s going to be a few weeks for device that would be, I would say, some level of complexity. Like a firewall and a load balancer but if we are talking about a switching platform it would be days. And what we typically model on the network elements is the most commonly deployed configurations. So it’s not going to be that long of an effort to get something out of the gate that is pluggable and usable in the run time environment.
14:11 Ethan: And then once those devices are integrated into NCX, NCX now has a model. It can talk to them, it can ultimately push configuration down into them. Do I have to interact with those end devices at all. Because you mentioned graphic user interface. You mentioned RESTONF API. It sounds like everything hides behind NCX at this point.14:28
14:31 Praveen: Right, so the NCX UI itself is model driven. So once customers develop these device models and service models, and once this is deployed into NCX platform, the platform as a part of its core services provides a model-driven UI and a model-driven API. So from a UI standpoint, if you want to consume the service out of the NCX platform, there is not a whole lot of development that is required in the NCX UI. You just have to go and do some Role based access control to make sure who can consume that service. And on the model device side, if you really are intending to make NCX as a single point of entry into your network. You can pretty much operate on the device itself directly from the NCX. Or if you don’t want to operate at the device level, you can go up to the service level and operate at the service level. At the service level, you will be more like deploying an application that translates to a bunch of calls like deploy VIP, deploy firewall rules and other aspects there. But the administrator is always welcome to go and operate against device.
Device Reconciliation
15:30 Praveen: And we also allow outo band management. We don’t expect the NCX to be the sole owner of the infrastructure. The reason is, a lot of things happen and not all things are typically orchestrated. And some things for example, the recovery from a security is an issue, may not wait for all of this devops to kick in. Maybe somebody is going to go and recover that issue manually. But NCX has smarts to discover that information back into the platform, so that the NCX is always up to date.
15:51 Greg: That’s a really key feature I think, because what you are saying there is, NCX configures the platform, but it doesn’t lock you out of configuring the CLI. So let’s say you got a router or a firewall and somebody goes in and adds a rule manually, you can choose to cope with that. That is, to reimport that and add it to your database.
16:11 Praveen: That is correct. And it actually serves two purposes Greg, sometimes, there things that are happening on the infrastructure is not intentionally. But how do you describe what is accident and what is intentionally. And that is actually where we have a policy base mechanism that says, if there is something that is done accidentally, we are going to describe that policy with the policy saying, if it is something to do with application delivery, NCX is the master. And anything that happens on the infrastructure, I want it to be rolled back automatically. So we are going to treat that as an accident. So there is going to be some configuration which NCX is not the master, but NCX is allowed to have super set of configuration in the inventory. There is a mechanism where we can roll it back, or to provide a great peace of mind to the operators and the administrators to say, any accidents, nobody is going to get woken up in the middle of the night. It will be rolled back if there is an accident. But at the same time we also have the smarts to make sure that we don’t keep getting into a cycle of rolling back any intentional change. So we just have to take care of it properly.
17:06 Greg: Now, let me just ask you, this is a bit of deviation, but, so in some companies that would be a good idea. Letting people configure to do a CLI, but at some point you actually want to stop people to doing things with the CLI. Could I do that too? Could I write a rule that says, this device shouldn’t be changed. The only thing making changes, should be NCX.
17:26 Praveen: That’s definitely where we are headed, that’s definitely on as a part of operations goal I would say with respect to the customers. And frankly speaking, the way it stands today, we are not really there. But the platform is definitely catered to accomplish that goal. That’s actually why we are building that much intelligence into the product.
17:45 Greg: So the one way to look at that is to say that customers aren’t actually working that way. You are saying that, so for me when you are saying, you couldn’t deploy in a brown field that is an existing network, this is one of the features that will let you start using NCX. Because NCX is still able to say, oh look, there are some new configurations there and I need to bring that into my model. You then bring that into the way the database, the NCX system knows about the change. And then it doesn’t work independently, the assets, it works with the assets, and the existing routers. So you don’t have to be all automation from day one. You could be CLI and automation both.
18:16 Praveen: Right, exactly. And they way to way to deploy a standardized services into the infrastructure where you have human intervention or any accident that is definitely on but I believe there are going to be some small intermediate steps to get to that goal.
18:33 Greg: I guess the other side to look at that is that there are other SDN platforms out there; other software platforms that each vendor has, and they might want you to use those to configure there devices. And this would allow you to live in partnership with all those other platforms too.
18:48 Praveen: Yeah, definitely, definetly, so we actually don’t intend to intend NCX to be doing everything out there. Because look at the overall ecosystem, there is billing systems, there is OSS system, there is ticketing systems. There are other NMS platforms, there are service monitoring platforms. So there are specialized areas where there are specialized components to take care of that problem space. And the NCX has that platform that specializes in orchestration only. And we are going to integrate smoothly using their native interfaces. So just like we interface with the device for example, to go and create VLANs, VRFs and SVI.. other aspects. We integrate similarly into the APIs that the Infoblox for example, provides for IP address management. Like APIs into the junos space or service now or science logic. So any of those platforms we can integrate smoothly into an ECO system and blend all our architecture together for the customers.
19:43 Greg: That makes sense and just to compare that, if you look at the way, say CISCO, ACI talk to its hardware, or it says we’ve got full control over that hardware. You can’t have CLI, we take control. And the ACI and the APIC controller does all the stuff. And if anything change, then it doesn’t quite throw to an air condition. But that’s not what is supposed to happen, right. So that’s a radical difference between you thinking of it, comparing it to other solutions out there. NCX is an orchestration platform, not an automation platform. And most of the other SDN, you know, things that manage networks aren’t actually orchestrating. They are just automating. I had a VLAN, I delete a VLAN, I create security groups, or I create Micro-segmentations within the network. But what you really want or what NCX tends to drive into is, this idea of transactions. That is, I am doing something somewhere else in the network. Now I need to drive a bunch of activities, create firewalls, deploy load balances, create full advancing configuration. It’s all about orchestration, not just automating VLANs on a switch.
20:43 Praveen: Right, exactly.
Service Assurance
20:46 Ethan: So I’ve got NCX installed its building services out for me. How do I know that, that service is in place. And we kind of touched on this where you mentioned some people could maybe make a change, and NCX could see it and put the change back. Are there other measurements or telemetry that NCX can ingest to kind of know that the system is operating as intended.
21:07 Praveen: Yes, as part of the overall umbrella that is. Service assurance that the orchestration platform does, is to ensure that policy that has been deployed stays deployed. And if at all any manual overrides that get reconciled into the NCX system, so that at any given time, at least from a configuration standpoint, we are set. And the next aspect is, okay, I have deployed a bunch of configuration. Is the configuration working as expected, or is the protocols and the features that I have deployed working as I’m expecting to work. That’s where some of the operational data come in. For example, if I go on and turn on routing like BGP routing, I actually want to see, okay if the routs have been learned. Some of those activities we can get information from the SNMP MIBs. Some of them we have to build more custom APIs, in some cases we will have to get the data using show commands. So apart from configuration, now the orchestration platform can actually dive into some of the operation side of the aspects. And we have the modelling to take care of that also. And within the device model that we have, that we have built, there is configuration data. And there is operational data, and the source for operational data is the APIs that provide operational data like SNMP and other APIs.
22:21 Praveen: So once we have this tool, now we can have a very reliable way to tell the operator or the consumer that whatever service that they have deployed is up and running. For example, if there is a vip, we can actually go and execute ping to the VIP address and figure out if the vip is actually reachable on a particular port, on a particular service. So that it’s not just configuration or a bunch of configuration that we have been able to push, but also giving a live feedback to the customer saying, it is actually working the way you intended it to.
22:48 Ethan: How deep can you go with those sorts of test and monitoring. You kind of like creating you own telemetry there. You are doing a health check on a service. You mentioned show commands. What about things like LLDP, is that interesting information to you?
23:02 Praveen: Right, we do use some of the information apart from the discovery mechanism, let’s say server is hooked up into the existing access pod in Data Center. So the way get notified is through a syslog or SNMP saying that the interface has gone up. What that means is that now I have to go and alert the upper layers, that whatever services they have provisioned to on board a server in an existing POD is up and running now. So that’s a conclusive proof. So we can go deep and wide so we have a same model based approach here. Whatever aspect you can model and what other aspects you can map in the API; the operational side of the APIs. You could possibly bring that into a service verification mechanism. So it’s definitely on for us we can take it that way.
23:48 Greg: When you say service verification, you are talking about like, I’ve just made a change, I now run a test to check that service is working as is, like as simple as a ping or creating a HTTP flow or something like that.
23:59 Praveen: Yes, exactly. So it is very much mimicking the behaviour of what a human operator would do after deploying configuration. So those sequence of steps you can do that.
24:11 Greg: So you want to deploy the firewall and a VLAN and some routing, and all the things you need for certain types of things. Then you actually want to run a flow through that to check that the firewall really works as promised. Otherwise there might be an error. So when you say service verification, you actually mean, just what the network engineer, he might type WGET, Curl the actual …/HTTP/IP Address and see if he gets a HTTP response, that’s basically what it is.
24:35 Praveen: That’s correct.
Multi-Tenancy
24:35 Greg: I want to come back to the topic of just multi-tenancy. You got a lot of customers, that’s a pretty big deal. Your means that your platform is not doing it once, you are actually doing it in a compartmentalized highly scalable way.
24:52 Praveen: Yes that’s definitely one of the big features of the NCX platform. And if you see where the enterprise structured, we have a campus branch and data center. And depending on the size and complexity of the enterprise, sometimes they manage the whole infrastructure themselves, like an insourced kind of mechanism, or the outsource this management to external provider where you have a large MSP. But the usecases are predominantly similar. If the enterprise is managing themselves or it’s managed by somebody else, it is still exactly the same thing that they do. In this case let’s say if the MSP needs to operate, the NCX has the platform. Now the challenge is, okay, who owns the platform? Is the customer leasing the equipment from the MSP or the customers owning the equipment or the customer is just using shared services like the hosted solution where they are getting some benefits out of the HVAC. So no matter how you see it look at it, the use cases is not that different, but it’s just. You have to segment it.
25:51 Greg: Yeah because if you are a managed provider, you’ve got 10, 20, 50, customers. If you are an enterprise, you might have a geographic distribution. You know the team in America’s and then down in Asia, and in Europe you might have three different tenants, so that they all manage their own properties. Or maybe you, you’ve got a data center and you want to have multi-tenancy. And you then you want to say, here is devops and you want to have legacy pre-production. And here is my production and here is my PCI compliant section, and they can all be tenants. What you are saying to me, I think is, that you can embrace all those use cases in your multi-tenancy model.
26:23 Praveen: Yes
26:23 Greg: And customers are doing that today?
26:26 Praveen: They are actually; one of the largest market segment that we address is the MSP market segment, apart from the enterprise and the telcos. So we are pretty active in this area.
KPI driven assurance with YANG models
26:38 Greg: So I’m going back to the model-driven service assurance. And I know models are very hard to understand. I’m still wrestling with them in my head, right. How do I measure, like a lot of entrprises are big on these key performances indicators, or KPIs or metrics to measure how the performance is going. How does your solution handle that?
26:54 Praveen: So apart from the services verifications, that’s more low level, verifying some of the traffic that’s passing through on some IP might be responding or not responding, the broader problem to be solved is, what sort of SLAs that we have promised to our customers. And how that SLAs can be translated to KPI. So KPI is a combination of health, performance… and availability metrics that could gather from the underlying infrastructure. And some of the KPI did maybe on the NCX itself when NCX is collecting the data. Or the KPI could come from an external service assurance platform in which case Anuta NCX would have modeled the KPI that excellent platform also with aspects of the KPI. And we provide a full state machine definition. I want even one to happen, I want even two to happen. And event one is on device one, event two is on device two. And I want these two events to happen within the window of five minutes and I want to do it for like three times before I take an action. So these kinds of state machine can be defined with the NCX platform. And the action itself is going to be some custom action that you would define as a service model. Let’s say that you see that that there is an interface that is flapping, and you want to change something on the infrastructure side. Let’s say you have a WAN connectivity and you are observing that some aspects of the circuit one is not performing well, you have to switch over to circuit two. And this is something that could be easily accomplished by creating a service and triggering that service by observing some data. That’s where the KPI comes in.
28:27 Greg: So you are actually defining the key performance indicators from your own operational data, your own statistics data. Your own statistics platform, or you could get the analysis from some external service assurance platform. So you’ve maybe you got some other application delivery platform such as what the ….load balancing vendors are getting into. You know one of those many other products in the application delivery space. And you can actually use that data to validate the KPIs.
28:52 Praveen: it would be an equipment vendor itself that provides the data or platforms like Science Logic. And the traditional NMS systems that actually work closely with the infrastructure. They collect some of them more heavy duty information. So we can collaborate with any company that can provide the data into the NCX platform.
Customer Deployments
29:03 Ethan: You guys have mentioned that you have a full solution here. This isn’t just for data centre, this isn’t just for service provider, you cover all sorts of domains. Okay. Let’s talk about some customers and use cases then, people that have deployed you in all different places. One of the things I am interested in particularly is to know how you fit into the WAN because when orchestration has gotten really interesting with all the SD-WAN plays that are going on out there and that can be a complex deployment, how do you play in that space?
29:29 Kiran: As you said the WAN is definitely going through a major transition. Anuta NCX is a perfect fit for such hybrid environment. We have customers that are using it with the traditional infrastructure, if you will, like CISCO, ISR..or Juniper SRX, .as well as the Riverbed Steelhead… They have used NCX to automate DMVPN configurations across hundreds of branch offices.
29:58 And we have some advanced customers who are deploying CISCO IWAN solutions. As you know CISCO IWAN has lots of smarts to detect the application, performance routing, policy based routing, QoS and then they have built the service models to automate the CISCO IWAN configurations and then we have managed service providers. They are looking at the trend of NFV virtralization and they are saying, why don’t we package the virtual SRX, the virtual CISCO CSR 1000V, the virtual steel head and offer it as a managed service to the enterprise customers.
30:41 For that, as praveen explained earlier, because of the multi tenancy in the platform, that are using NCX to offer virtual CPE based solutions to their managed enterprise customers.
30:52 Finally as you mentioned, many enterprises as well as service providers are looking at SDWAN as a way to cut down their MPLS expenses. But they can’t switch over, overnight to this new technology so they are going through this migration where you have the traditional infrastructure as well as the SDWAN infrastructure.
31:14 Again NCX fits very nicely when you have multi vendor environment with multiple technologies, each in it’s own maturity phase and NCX will provide that agnostic layer to the business, so for example, if someone goes to the NCX portal and says, I would like to order a remote branch, depending upon their SLA as well as depending upon the significance of that location, the NCX can figure out, okay, I would like to put it on the traditional infrastructure or the SDWAN infrastructure as well.
31:47 So, I would be building a model of what I want my branch to look like. You just listed both architectural scenarios and then components that could be a part of that. I am going to build that out into my service model and well, it sounds like I got a couple of options. I can start out my branch office green or then brown field if I am transitioning from one set of services to another. NCX will get me there as well.
32:13 Kiran: Exactly. It’s the perfect fit when you are going through a transition and you have a lot of traditional infrastructure and you are also taking on the new technologies. In the same context, many enterprises are also looking at SDN controllers. You have CISCO, vmware, HP, Nuage, all these SDN controllers as praveen mentioned, they bring a lot value that again NCX fills the gap.
32:41 You are trying to introduce the SDN solution back into your infrastructure. For example, a large service provider in APAC… they are using Nuage, VSP to enforce policies but then the missing pieces such as VNF management, policy configuration as well as integration with open stack is all handled by the NCX platform.
Integration with SDN, SD-WAN, OpenStack and Northbound Portals
33:03 Ethan: This is kind of interesting here because someone would say, oh well, I think the NCX platform is SDN controller, but it isn’t in fact, it’s really orchestration. Is really what we are about here and the SDN controller may have some specific ideas about what the network is supposed to accomplish and how it does that but to communicate downward those devices, would it be integrating with Anuta as you said filling in the blanks?
33:29 Kiran: Yes, so we treat SDN controller as another infrastructure, so when we are talking to CISCO ACI, we consider the whole ACI fabric as one device. When we speak to F5, let’s say it has a F5-BIG IQ platform, like maybe there’s a bunch of F5 LTMs, then we can communicate with the F5 BIG-IQ. Similarly with Contrail, similarly with Nuage VSP. So, Anuta NCX sits on top of this legacy infrastructure, SDWAN infrastructure, SDN infrastructure as well as the NFV infrastructure.
34:03 Ethan: Okay. So, the Anuta would be at the head here, and again, that was interesting and that’s the SDN controller sitting underneath Anuta and I am doing my virtual, waving my arms, you can actually see it. [chuckles] And then we end up with an SDN cotroller that is presenting some amount of networking infrastructure that controls as one unified object up to Anuta. So Anuta could send service intent to the SDN controller which then sends that intent down to the infrastructure that sits underneath it?
34:32 Kiran: You got it.
34:34 Ethan: And again, you mention there is a Nuage integration, open contrail, are there other notable platforms that you have integration with there?
34:41 Kiran: So we also integrate with HP Helion Open Stack because Open Stack as we see has a lot of promise and again using the Open Stack as a virtual infrastructure manager, we are delivering the virtual CPE solution. Open Stack does all the virtual appliance management. We also developed a neutron plug-in that goes into the Open Stack as well. I believe it’s called ML2 plug-in…now.
35:10 Ethan: Yea, yea, they did, they changed it.
35:14 Greg: Every other week it’s got a different name or something.
Performance and Scale
35:17 Greg: Okay, so one of the things we talked about earlier was manage service providers and some of those manage service providers, big, they’ve got the support, not just big customers but lots of big customers. The question that I didn’t ask at the time is, how big does NCX scale?
35:29 Praveen: So the customers that we are referring to would have anywhere from couple of thousand devices to half a million devices, that’s actually the scale that we are looking at. And the way we have built the software is that, it could cater to infrastructure that’s local within a data centre or the infrastructure could be remote with a main branch office or camps or a multiple data center kind of deployment.
35:52 So the software can be deployed in a fashion where it’s horizontally scalable and some of the components that work closely with the device or the infrastructure, they can be deployed on a remote location and this model actually works in a very neat fashion especially for the very large MSP, where typically sometimes they are deployed, their manageability software at customer prem…so that MSP can deploy the NCX master in their own data centre but the remote controllers can stay within the customer environment.
36:28 Same thing applies for a large enterprise because they are also geographically dispersed and in some cases we have worked with large financial institutions that have huge data centres in North American theatre and they have data centres in EMEA and the Asia Pac. but they still need to provide a cohesive way of deploying services like. End-to-end.. in which case we have to deploy the NCX software in a fashion where it is federated across different geographies and we have to scale pretty massively for all of those environments, and we have a micro services based model as well. So that we can scale out the exact component where scaling is required, for example, we are doing an initial discovery. In that case the only company that will be scaling out is the discovery component. When we have to do inventory. On a schedule basis, we can go and scale out the inventory component.
37:19 Similarly, when it comes to provisioning, we are going to send a bunch of configurations so then, we are going to scale that out appropriately so that we can achieve the expected throughput, or the performance goals with respect to orchestration and scale as a side effect.
Micro Services Architecture
37:36 Ethan: Is that scaling automatic because you said micro services architecture…which sounds to me like there is some sort of a scheduler that is monitoring load perhaps and can as you say, we are doing a big discovery now and them ramp up multiple instances of discovery engine to make sure you have enough horsepower to get the job done?
37:52 Praveen: Yes, so the scaling is automatic and driven by a policy so we just want to make sure that some aspects of the system gets some dedicated amount of resources and then some aspect of the system can be scaled out. All of this goes into the policy definition as to what is the structure of what I am deploying, is it going to be for four or five components and within the components we have these specific functions that can be scaled out.
38:18 So just a matter of policy but as long as the policy is in place, can take care of the scaling horizontally and also from an operational point of view, all of these components are going to be managed centrally so any software images that we have to upgrade in all of this micro services, so that is something that we take care from a central controller, so that we are not complicating some of the NCX software maintenance itself once we have this multiple instances in parallel.
38:44 Ethan: You mention federation, also geographic distribution of NCX controllers better than federated. Is that what we mean by a centralized controller here?
38:54 Praveen: Yes, centralized master but the master itself can be replicated to just make sure that we accommodate for disaster recovery. So, we can duplicate the master in side one site, two site, three and at the same time, the data base itself gets replicated and we support data bases that are designed for this purpose like Cassandra that can be deployed in a DR fashion that can spread across multiple geographical locations. It’s a fairly mature scalable platform and we have taken a lot of the innovations happen in a large enterprise customers, large companies like Google, Facebook, they kind of use this technology fairly well because they cater to customers in this multiple theatre. They have to have scale data and they have to perform.
39:35 So we kind of take some inspiration from them and ultimately what we are looking at for the orchestration is also similar type of problem space, I would say from one aspect, it’s big data. There is so much amount of data to work with and some of the ways that all of these large companies like Facebook, LinkedIn, the way they solve it. And even Netflix, the way they solve it is how we have approached the platform also, that we really have to work with a huge amount of data.
40:04 And then again, from a network standpoint, network data, configuration data, operation data, statistics and analytics; all of this data is what build the orchestrate the engine on top of – so we are built for that purpose, to scale massively and also to perform.
NCX Installation Specs
40:18 Ethan: Again, that doesn’t mean that Anuta is strictly for large or huge customers, meaning small shops can use this platform as well?
40:25 Praveen: That is true, that is true. The way we scale out, the way the footprint looks is pretty much based on the requirement. So when the requirement is for a couple of thousand devices, we are not going to need more than one node of software and it will literally be just a footprint of..4 GB RAM and then maybe two VCPUs…20 GB of hard disk and so it can be as small as that.
40:50 if The requirements require us to scale horizontally and it can be a lot of different number of nodes…it can be more than an hundred nodes that we might have to scale out depending on, if it is half a million device or so. So, it’s something that can cater to both customer basis.
Wrap-Up
41:04 Ethan: Well guys, thank you for presenting Anuta NCX to us and getting us caught up in where things are at. This is obviously a mature product that’s got lots of miles under it now, as I can tell just by just by the way you have added certain features and things you have done. You have been working with people that are in using this product, have come up with features and functions they’ve needed and you have delivered on that. Kiran, let me flip the microphone back to you. How can people find out more about Anuta? Any final comments and thoughts that you want to share with the audience?
41:32 Kiran: Ethan, yeah. I want to leave the audience with a small teaser. We are going to announce a very large deployment out of Asia Pac., so please watch out for it. You would be quite surprised at the scale with which we have deployed this solution and it’s going to revolutionize, that SP in that region. For more information and to keep up to date with us, please follow our blog – Anutanetworks.com/blog and for Packet Pusher listeners, we are specifically dedicated at particular segment of the website…you can find all the relevant data sheets, case studies of all the use cases we just discussed including platform features.
Raffle for Amazon Echo
42:17 Just for Packet Pushers listeners, we are running a raffle and one lucky winner will receive the Amazon Echo. The fantastic ALEXA, you can bring it home. So please go check it out, Anutanetworks.com/packetpushers.
42:33 Ethan: Thanks very much Kiran.
42:34 Greg: Cool, I’ve always wanted one of those.
[laughter]42:39 Greg: Alexa, Configure my network.
42:40 Ethan: There you go.
[laughter]42:44 Speaker: You know what my toddler figured out. He put the Apple Siri next to ALEXA and instantly becomes a comedy show.
[laughter]42:53 Ethan: Again, look to Anutanetworks.com/packetpushers if you want to find out more about Anuta and enter their contest for the Amazon Echo where you can have ALEXA do stuff for you.
43:06 That is it for Packet Pushers today. We thank Anuta networks for being a sponsor. You can find this show and many more free technical podcast along with our community blog at Packetpushers.net. Of course you can follow us all over social media on Twitter, Packet Pushers, LinkedIn, Facebook and if you would rate us on i-Tunes we would appreciate that.
43:21 And last but not least, remember that, too much networking would never be enough.
43:25 END
– Chandra Manubothu, August 11, 2016.