 Skip to content
Skip to content 

This is the last blog in our multi-part “Massive Scale” series. In previous blogs, we covered the scalability aspects of each ATOM function (workflow automation, service orchestration, and compliance and analytics). We walked through various customer case studies that focused on ATOM’s automation and monitoring capabilities for large networks. In this final piece, we will discuss the broader architecture of the ATOM platform that enables horizontal scaling.
Many traditional automation solutions that are available today can only support a few hundred to a few thousand devices. In contrast, to automate up to 500,000 devices such as in large service providers and enterprises situation, an automation platform needs to be scalable and resilient. A high level of complexity is often introduced even if the task is a simple configuration change when multiplied by the number of devices. Ultimately, this complexity needs to be managed efficiently through a single pane of glass. Many infrastructure providers promise to deliver, but few have the capability to do so.
Traditional Approaches to Scalability
To support large networks, enterprises typically adopt a solution consisting of several different components. However, such solutions come with multiple drawbacks. First, each of these automation systems have different licensing requirements. Second, troubleshooting can be difficult if an IT administrator needs to maneuver between several different systems. The overall operational expense will also be high as one needs to learn different platforms. This process is not sustainable unless a company has extensive support staff.
Additionally, if de-provisioning is a requirement, one has to de-provision from the other systems across multiple domains. Consider the impact to report generations. When one has to generate a billing report, ideally, it needs to span different systems. Using a manual approach or stitching reports across different systems is slow and not scalable. Ensuring consistency across different systems requires massive infrastructure to capture and query data. Furthermore, service providers and operators need to maintain device data in a time-series database for historical purposes.
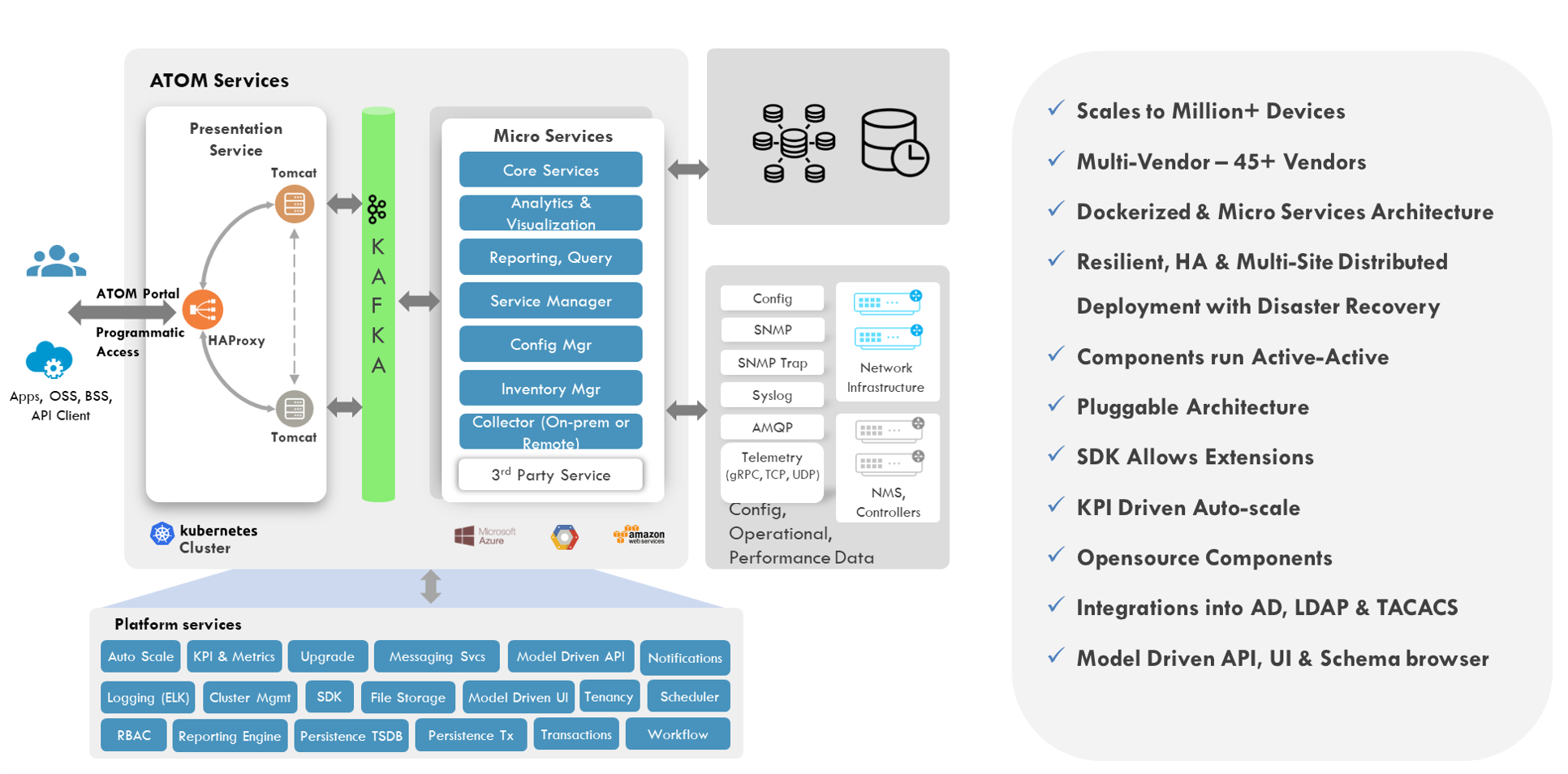
The ATOM Microservices Architecture
To achieve a massive scale, the application’s fundamental architecture must be componentized, agile, and stateless. ATOM is built on a modern stack that leverages Docker and Kubernetes to provide horizontal scalability. All microservices in ATOM, except for databases, are stateless and utilize the Kafka streaming platform for communication. The state of the system must also be stored in highly available databases
Some of the essential attributes to measure the capabilities of a highly scalable platform are the following:.
Response Time: This refers to the time taken by the platform to respond to requests. The request could be presented through a user form or an API call from northbound entities. Response time is calculated as the total application time needed to process the request and acknowledge the user.
Throughput: This refers to the number of service transactions executed per unit of time. Services include workflow automation, service orchestration, compliance enforcements, monitoring and closed-loop automation. Throughput depends primarily on two factors.
- Response Time: A low response time leads to a higher number of transactions per unit of time, thereby increasing the overall throughput.
- Concurrency: This represents the platform’s ability to handle multiple requests simultaneously. Parallel execution supported by infrastructure and underlying hardware, provides higher throughput.
Scale factor: The time taken to service one transaction must be the same as the time taken to service one million transactions. To service one transaction, a single component is adequate. However, to service a million transactions, the platform needs to spawn several microservices and load balance across them all. Spawning multiple instances increases communication latency and reduces throughput. A well-architected platform provides a constant scale factor of 1:1.
Availability: This is a ratio of the amount of time the platform is available to service requests during a given time window. Availability is reduced anytime the application is not performing normally due to scheduled or unscheduled interruptions.
ATOM consists of the following five capabilities to provide a highly scalable and available platform.
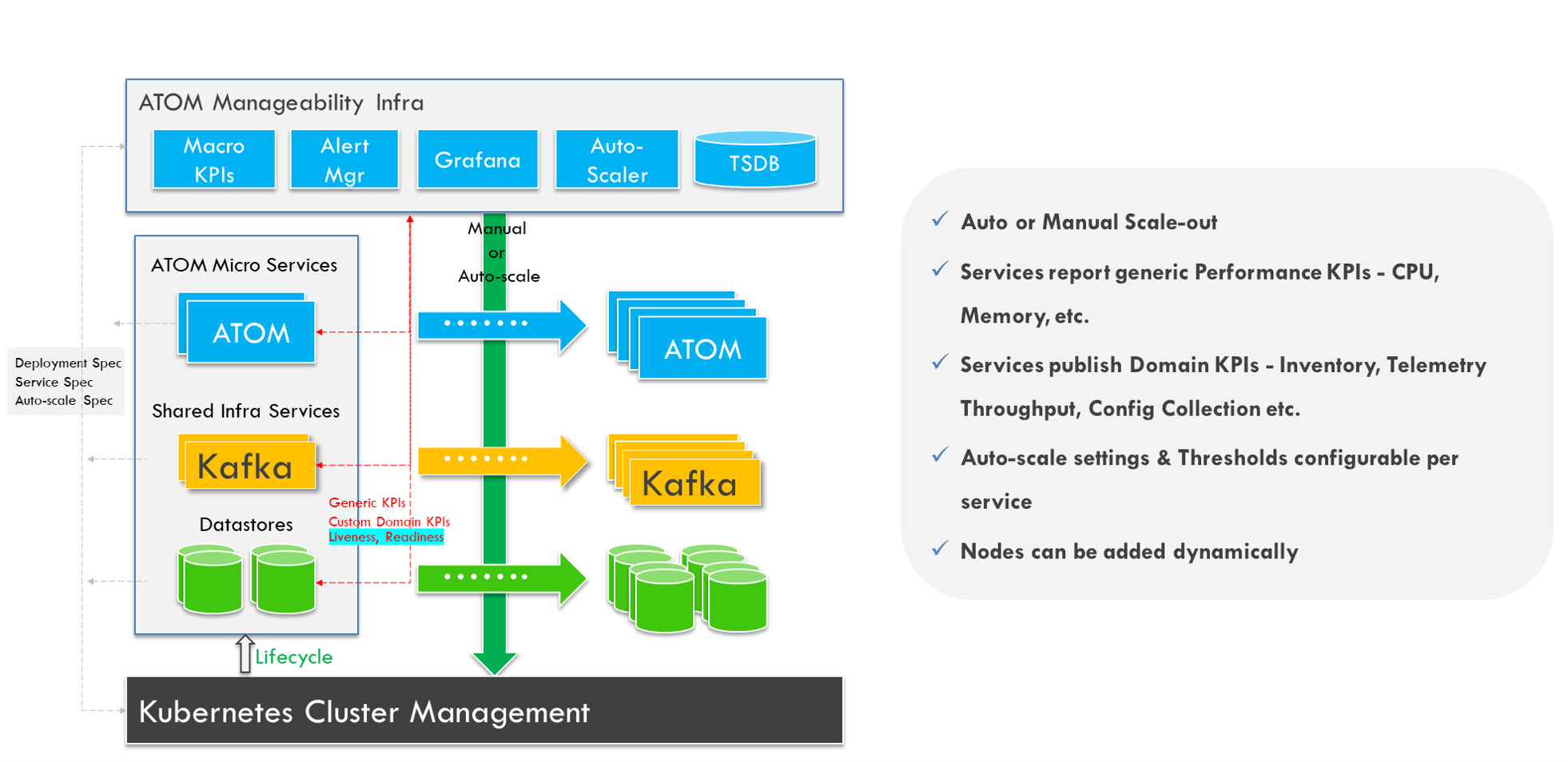
Auto or Manual Scale-Out
The ATOM platform is composed of many microservices that can be scaled-up or scaled-down based on specific network conditions. It is microservices architecture uses containers that reduce the overall system footprint and scale horizontally to an unprecedented 1 million+ devices. The platform can be deployed in Kubernetes clusters either in a local data center or a cloud-based deployment.
The ATOM platform leverages Kubernetes to manage and orchestrate Docker containers. ATOM deployment scripts configure the minimum number of replicas necessary to meet the predefined performance requirements. ATOM continually monitors the state of the deployment. The overuse of resources alerts the ATOM deployment engine to scale-out affected components automatically. Administrators can also scale-out specific ATOM components on-demand. As a result, ATOM deployment provides administrators with the flexibility to add compute and storage nodes dynamically as needed. The result is zero over-provisioning of resources thereby reducing expense.
Self-Monitoring and Alerting
ATOM monitors all microservices for throughput, latency, and availability and enables operators to visualize every component’s performance details. Performance data includes resource utilization ( CPU/MEM/HDD) for each microservice, minimum, maximum, and average latency across components, disk utilization and latency of the databases, and much more. ATOM also allows operators to set thresholds to define the baseline behavior of the ATOM platform. Examples of baseline thresholds include maximum CPU utilization for ATOM core components, maximum allowed end-to-end latency for service provisioning, the minimum number of metrics to be computed every second, and more. Upon violation of any threshold, the ATOM deployment engine can alert the administrator and undertake predefined remediation actions.
Remote and Centralized Agents
ATOM agents can be deployed remotely, closer to the devices, to reduce latency and increase throughput. Each agent can manage thousands of devices and communicates securely with the ATOM core. For use cases where latency is not a significant concern for an operator, ATOM agents can be deployed centrally.
High Availability and Flexiblity
An essential factor in providing high throughput on a consistent basis is high availability. High availability ensures that the platform can operate at maximum capacity even upon failure of one or more components. All ATOM components are resilient and run in active-active mode. Failure of any components immediately spawns a duplicate instance to prevent any impact to throughput or latency. ATOM also supports multi-availability-zone deployment that enables operators to distribute ATOM components across multiple sites and improve ATOM reliability and resiliency.
High Resiliency and Hitless Upgrades
ATOM’s microservices architecture enables auto-scale and resiliency. The backup/recovery management capability facilitates the recovery of failed microservices components. If three microservices are running and one fails, the other microservices components can continue to serve critical requests. The metrics management unit also displays the performance of each microservices as well as the health of the Kubernetes cluster. Logging functionality displays the generic ATOM platform logging information. In addition, the tracing component reports how requests are flowing across the connected microservices. Finally, ATOM provides hitless upgrades. Upgrading or patching the platform will not impact services currently running within the platform.
ATOM’s flexible architecture allows organizations to start small and grow big. The ability to scale and distribute individual components enables administrators to plan their automation and monitoring requirements precisely. Deployment of every ATOM feature discussed in this blog series – Workflow Automation, Service Orchestration, Compliance Management, and Monitoring – can be controlled and fine-tuned to business needs.
The explosion of data creation requires a highly scalable network automation and monitoring solution. Emerging technologies such as 5G, IoT, Wi-Fi 6 and mobile edge computing will also increase the complexity of existing networks. Enterprises must find solutions that can support rising business demands and provide a unified, comprehensive, and intuitive experience. The Anuta Networks ATOM platform, given its microservices based architecture delivers the required scale to match any organization’s growing needs.


